دنیای علم و تکنولوژی
اخبار و مقالات مربوط به دنیای علم و تکنولوژی ترجمه شده از منابع معتبردنیای علم و تکنولوژی
اخبار و مقالات مربوط به دنیای علم و تکنولوژی ترجمه شده از منابع معتبردرباره من
 وبلاگ رسمی اصغر ناصری
این وبلاگ با هدف ارائه مطالب آموزشی تهیه می شود و قصد دارد به دانشنامه کوچکی از علوم و فنون تبدیل گردد.
ادامه...
وبلاگ رسمی اصغر ناصری
این وبلاگ با هدف ارائه مطالب آموزشی تهیه می شود و قصد دارد به دانشنامه کوچکی از علوم و فنون تبدیل گردد.
ادامه...
دستهها
- تصاویر جالب علمی 60
- اخبار علمی 116
- تاریخ علم 21
- مقالات علمی 187
- حقایق علمی 29
- پرسش و پاسخ علمی 4
- تکنولوژی نظامی 170
- مشاهیر 11
- معرفی وبسایت علمی 10
- سخن بزرگان 4
- تفریح و سرگرمی 1
- شگفتیهای طبیعت 6
- مسابقه علمی 6
- زبان انگلیسی 18
- دیرین شناسی 35
- مهندسی مکانیک 56
- دنیای ریاضیات 54
- فایل های قابل دانلود 8
- پزشکی و سلامت 88
- ترین ها 38
- کنکور 1390 14
- نمونه سوال امتحانی و آزمون 20
- معرفی نرم افزار 4
- واژه نامههای تخصصی 1
- آزمایش های ساده و جالب فیزیک 4
- کنکور 13
- تکنولوژی نفت و حفاری 5
- بانک مقالات علمی 3
- آیرودینامیک و پرواز 6
- استانداردهای مهندسی 6
- محیط زیست 39
- باستان شناسی 5
- پروژه درسی و سمینار 5
- برنامه نویسی کامپیوتر 11
- رپرتاژ آگهی 1
ابر برجسب
کووید 19 کرونا ویروس ریاضیات جنگنده هواپیما ستاره زمین لرزه گرمایش جهانی F-35 موشک کنکور بمب افکن سیاهچاله جنگ جهانی دومبرگهها
جدیدترین یادداشتها
همه- کوارک ها: اجزای سازنده ماده
- آموزش زبان برنامه نویسی پایتون با مثال
- سمی ترین حیوانات طبیعت
- کهن ترین مجسمه ساخت انسان
- راه حل اویلر برای مساله بازل
- ژنتیک: چگونه ویژگیهای خود را از نیاکان به ارث میبریم؟
- برنارد ریمان، آفریدگار هندسه نا اقلیدسی
- ابتذال چیست؟ ریشه آن کدام است؟
- اتمها از کجا آمدهاند؟
- پیری: با گذشت عمر چه اتفاقی برای بدن می افتد؟
- مسایل حل شده از معادلات دیفرانسیل
- لئونارد اویلر
- بخشهای مختلف هواپیما و کارکرد آنها
- انسان بر لبه انقراض
- ساخت بزرگترین هواپیمای حامل پهباد توسط چین
بایگانی
- آبان 1404 2
- مهر 1404 3
- شهریور 1404 3
- مرداد 1404 2
- تیر 1404 2
- خرداد 1404 3
- اردیبهشت 1404 1
- فروردین 1404 1
- اسفند 1403 1
- بهمن 1403 2
- دی 1403 1
- آذر 1403 1
- مهر 1403 1
- شهریور 1403 3
- مرداد 1403 1
- تیر 1403 3
- خرداد 1403 4
- اردیبهشت 1403 3
- فروردین 1403 2
- اسفند 1402 7
- بهمن 1402 2
- دی 1402 3
- آذر 1402 3
- آبان 1402 2
- مهر 1402 5
- شهریور 1402 4
- مرداد 1402 12
- تیر 1402 12
- خرداد 1402 5
- اردیبهشت 1402 6
- فروردین 1402 8
- اسفند 1401 6
- بهمن 1401 9
- دی 1401 2
- آذر 1401 3
- آبان 1401 1
- مهر 1401 1
- شهریور 1401 4
- مرداد 1401 7
- تیر 1401 12
- خرداد 1401 10
- اردیبهشت 1401 12
- فروردین 1401 4
- اسفند 1400 4
- بهمن 1400 7
- دی 1400 2
- آبان 1400 5
- مهر 1400 9
- شهریور 1400 1
- مرداد 1400 3
- تیر 1400 6
- خرداد 1400 7
- اردیبهشت 1400 8
- فروردین 1400 7
- اسفند 1399 12
- بهمن 1399 11
- دی 1399 1
- آذر 1399 7
- آبان 1399 2
- مهر 1399 1
- اردیبهشت 1399 7
- فروردین 1399 33
- اسفند 1398 13
- بهمن 1398 9
- دی 1398 1
- خرداد 1398 4
- اردیبهشت 1398 7
- بهمن 1397 5
- دی 1397 5
- آذر 1397 2
- آبان 1397 3
- مهر 1397 3
- شهریور 1397 1
- مرداد 1397 7
- تیر 1397 7
- خرداد 1397 2
- اردیبهشت 1397 6
- اسفند 1396 3
- بهمن 1396 5
- دی 1396 4
- آذر 1396 8
- آبان 1396 6
- مهر 1396 5
- شهریور 1396 6
- مرداد 1396 10
- تیر 1396 9
- خرداد 1396 5
- اردیبهشت 1396 3
- فروردین 1396 8
- اسفند 1395 3
- بهمن 1395 3
- دی 1395 1
- آذر 1395 4
- آبان 1395 2
- مهر 1395 7
- شهریور 1395 5
- مرداد 1395 1
- تیر 1395 3
- خرداد 1395 1
- اردیبهشت 1395 1
- فروردین 1395 3
- اسفند 1394 8
- بهمن 1394 2
- دی 1394 1
- آذر 1394 3
- آبان 1394 2
- مهر 1394 1
- مرداد 1394 1
- تیر 1394 2
- فروردین 1394 1
- اسفند 1393 4
- بهمن 1393 2
- دی 1393 1
- آبان 1393 1
- شهریور 1393 1
- مرداد 1393 1
- تیر 1393 3
- اردیبهشت 1393 7
- فروردین 1393 1
- اسفند 1392 2
- بهمن 1392 8
- دی 1392 6
- آذر 1392 16
- آبان 1392 14
- مهر 1392 19
- شهریور 1392 17
- مرداد 1392 6
- تیر 1392 2
- خرداد 1392 5
- اردیبهشت 1392 9
- فروردین 1392 1
- اسفند 1391 5
- بهمن 1391 8
- دی 1391 6
- آذر 1391 8
- آبان 1391 5
- مهر 1391 12
- شهریور 1391 7
- مرداد 1391 2
- تیر 1391 6
- خرداد 1391 7
- اردیبهشت 1391 8
- فروردین 1391 13
- اسفند 1390 7
- بهمن 1390 6
- دی 1390 11
- آذر 1390 2
- آبان 1390 6
- مهر 1390 4
- شهریور 1390 5
- مرداد 1390 8
- تیر 1390 15
- خرداد 1390 25
- اردیبهشت 1390 11
- فروردین 1390 1
- اسفند 1389 13
- بهمن 1389 12
- دی 1389 5
- آذر 1389 3
- آبان 1389 6
- مهر 1389 7
- شهریور 1389 6
- خرداد 1389 1
- اردیبهشت 1389 3
- اسفند 1388 7
- بهمن 1388 10
- دی 1388 11
- آذر 1388 7
- آبان 1388 17
- آذر 1387 1
- آبان 1387 9
- مهر 1387 5
- شهریور 1387 1
- مرداد 1387 3
- تیر 1387 7
- خرداد 1387 5
- اردیبهشت 1387 1
- فروردین 1387 3
- اسفند 1386 3
- بهمن 1386 9
- دی 1386 19
- آذر 1386 19
- آبان 1386 7
تقویم
آبان 1404| ش | ی | د | س | چ | پ | ج |
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
جستجو
موتورهای جستجوی وب چگونه کار میکنند؟
منبع اصلی: Webopedia
ترجمه: اصغر ناصری - زمستان 1391
موتورهای جستجو ابزار اصلی یافتن اطلاعات در پهنه عظیم وب جهان گستر هستند. بدون موتورهای جستجوی پیشرفته، یافتن اطلاعات مورد نظر در اینترنت تقریبا غیرممکن خواهد بود مگر این که آدرس URL صفحه وب مورد نظر را دقیقا بدانید. در این مقاله نگاه کوتاهی خواهیم انداخت به نحوه کار کردن موتورهای جستجو و عواملی که برخی از آنها را در صدر توجه کاربران قرار میدهد.
وقتی افراد از واژه موتور جستجوی وب استفاده می کنند معمولا منظورشان فرم های جستجویی است که امکان جستجو در میان اسناد HTML گردآوری شده توسط برنامه ای به نام روبوت را میدهند.
اساسا سه نوع موتور جستجو وجود دارد: آنهایی که توسط روبوت عمل گردآوری اطلاعات را انجام می دهند و به نام خزنده (crawler)، مورچه (ant) یا عنکبوت (spider) خوانده می شوند (زیرا عملی مانند خزیدن در پهنه عظیم وب و گردآوری تدریجی داده را انجام می دهند) و آنهایی که اطلاعات آنها توسط افراد گردآوری می شود و بالاخره موتورهای جستجویی که ترکیبی از هر دو عمل را انجام می دهند.
موتورهای جستجوی مبتنی بر روبوت از نرمافزارهای خودکار استفاده می کنند. این نرمافزارها یک وب سایت را بازدید کرده، اطلاعات موجود در صفحات آن را خوانده و متا تگ های سایت را بررسی میکنند. همچنین لینکهای موجود در هر صفحه را نیز شناسایی میکنند تا صفحاتی که لینک ها به آنها متصل میشوند را نیز بدین ترتیب مورد بازدید و نمایهسازی قرار دهند. روبوت تمامی اطلاعات گردآوری شده را به مخزن داده مرکزی میفرستد تا در آنجا اطلاعات نمایهسازی شود. منظور از نمایهسازی ذخیره کلید واژههای اصلی همراه با آدرسی است که این کلید واژهها در آنجا مشاهده شدهاند. روبوت بطور دورهای وب سایتهای قبلی را بازدید میکند تا تغییر اطلاعات موجود در آنها را ثبت کند.
موتورهای جستجویی که توسط انسانها تغذیه می شوند تنها اطلاعاتی را گردآوری و نمایه میکنند که توسط عوامل انسانی به آنها ارسال شده است.
در هرحال، وفتی عبارتی را در موتور جستجو می کاوید، در حقیقت نمایه ای را جستجو می کنید که موتور جستجو از پیش آماده و ذخیره کرده است. بنابراین واقعا وب را جستجو نمی کنید. این نمایهها بانک های اطلاعاتی غول آسایی از تریلیون ها آدرس می توانند باشند. به همین دلیل برخی نتایجی که موتورهای جستجوی بزرگی مانند Yahoo یا Google بر میگردانند لینک های غیرمعتبر یا مرده هستند. از آنجایی که نتایج جستجوی مبتنی بر نمایه هستند، اگر نمایه مرتب بروز نشود ممکن است حاوی اطلاعاتی مربوط به صفحاتی باشد که دیگر در وب موجود نیستند.
موتورهای جستجوی مختلف از الگوریتم های اختصاصی خود برای رتبه بندی نتایج استفاده میکنند. به همین دلیل برخی موتورهای جستجو بهتر و سریع تر شما را به نتیجه مورد نظر میرسانند.
یکی از عناصر اصلی مورد پویش الگوریتم های جستجو، تعداد و مکان ظهور کلیدواژه ها در یک صفحه وب است. هرچه تکرار کلیدواژه ای در یک صقحه وب بیشتر باشد، موتور جستجو اهمیت بیشتری برای آن صفحه قایل شده و آن را در نتایج جستجو در رده بالاتری قرار می دهد. البته الگوریتم های مورد استفاده موتورهای جستجو روز بروز حرفه ای تر می شوند تا صفخات قلابی با محتوای بی ارزش را تشخیص دهند.
نگاهی به تاریخ موتورهای جستجو
اولین ابزار جستجوی اینترنت در سال 1990 ابداع شد که Archie نام داشت. این ابزار فهرست های سبسبه مراتبی از تمام فایل هایی که روی سرورهای بدون نام FTP بودند تولید می کرد و بدین ترتیب یک بانک اطلاعاتی قابل جستجو از نام فایل ها ایجاد مینمود.یکسال بعد Gopher پا به عرصه گذاشت که می توانست اسناد ایجاد شده با متن ساده را شناسایی و نمایه کند. ورونیکا و جاگ هد دو ابزار فرعی برای جستجوی سیستم نمایه گوفر بودند. اولین موتور جستجوی واقعی وب توسط ماتیو گری در 1993 ابداع شد و Wandex نام داشت.
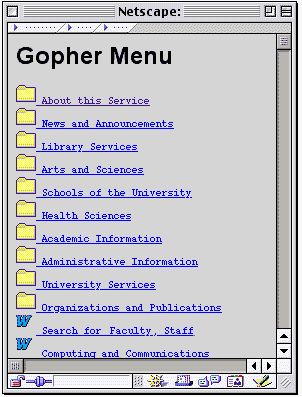
نمونه ای از فهرست های Gopher
در مارس 1996 دو دانشجوی دانشگاه استانفورد به نام های لری پیج و سرگئی برین پروژه ای تحقیقاتی به نام موتور جستجوی گوگل را آغاز کردند. این پروژه تحقیقاتی دانشگاهی بتدریج به یکی از بزرگترین و موفق ترین موتورهای جستجوی وب تبدیل شد و هم اکنون کمپانی گوگل در زمره بزرگترین شرکت های دنیای کامپیوتر و اینترنت محسوب می شود. تصویر زیر صفحه موتور جستجوی گوگل در سال 1998 را نشان می دهد:
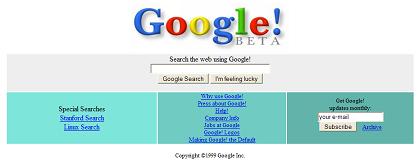
برای اطلاعات بیشتر به این مقاله مراجعه کنید:


























